AWS offers a plethora of useful tools, but as a DevOps Engineer, the Systems Manager has been a godsend. Systems Manager works by installing the SSM Agent on the instances you wish to manage. Through this agent and using a set of IAM capabilities, the agent can perform management tasks on your server inventory.
I love Systems Manager because it removes a lot of overhead for me in my daily work. Here’s an example: Recently we upgraded the operating system on our servers, and noticed that as a result, the timing mechanisms on our servers were off. There was a relatively quick fix, but it had to be deployed across all our (100+) servers, which would have taken hours. Instead, I wrote one script Document in Systems Manager, and (after safely testing it on one or two dev servers first), deployed the change to all servers in one fell swoop.
One of the great things about Systems Manager is that you can create your own Documents (either Automation documents, or RunCommand documents) to execute your own scripts. Or, to trigger existing scripts within your own script. Using this capability, we were able to create a script to schedule maintenance windows, perform patching, and notify important groups along the way. I thought I would share what we learned to help anyone else going through this process.
About SSM Documents
Documents is the term AWS uses to describe scripts, written in either JSON or YAML, which can be executed against your server inventory. Some are short and simple. Others are more complex, with hundreds of lines of code to be executed. Documents typically fall into one of two groups: RunCommand, or Automation. The difference lies mainly in the formatting. Automation Documents are typically workflows with several steps triggering other Documents to perform routine tasks. For example, one Automation we use assigns IAM roles that allow the server to write to CloudWatch logs (an Association). RunCommand Documents, by contrast, are mainly scripts or commands to run.
AWS has a number of Documents pre-made for you to use, namely, AWS-RunPatchBaseline which we will use later on. You can create your own documents as well, in JSON or YAML formats. I highly recommend using the pre-made documents as an example for syntax.
To run a RunCommand Document, you can trigger it to run from the RunCommand section. If your Document is an Automation Document, you can trigger it from the Automation section. You can register either Automation or RunCommand Documents within Maintenance Windows to run at a scheduled time if desired.
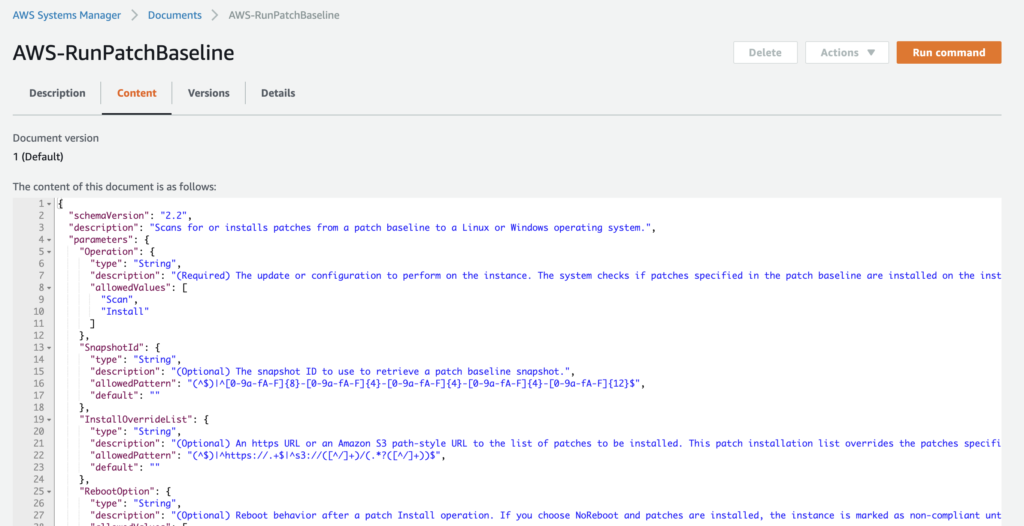
About AWS-RunPatchBaseline
The AWS-RunPatchBaseline Document is an especially useful document. This document uses the baseline for patching you have selected for your servers (under the Patch Manager section). For example, if you use CentOS Linux servers, you can use the pre-defined CentOS patch baseline to receive CentOS patches.
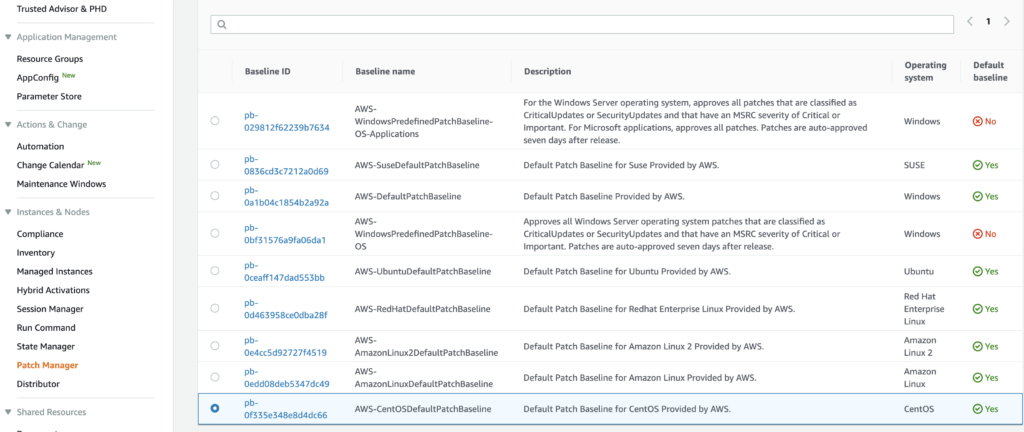
You can organize your servers running the SSM agent into various patching groups, to identify which servers should be patched together. In our case, the option to Create Patch Groups wasn’t functioning properly. But to manually configure the Patch Groups, you can add Tags to the server instances you wish to patch. The Key should be “Patch Group” and the Value can be whatever name you wish to give the patch group. For example, we originally divided patch groups into Develop, Staging, Production. But you can choose whichever groups make sense for your organization.
Automating Patching
Running the AWS-RunPatchBaseline command during your designated maintenance windows, on lower-level testing environments like Develop and Staging is one thing. Patching production is another thing entirely. The AWS-RunPatchBaseline command installs patches and updates to packages, but in order for the device to actually register the changes and show “In Compliance” (on the Compliance page), a Reboot has to take place.
While rebooting the server usually takes a minute or less time to complete, it can be disruptive to end users and support users. With that in mind, we should consider scheduling the patching with proper maintenance windows in our status pages, and in monitoring tools (Pingdom, etc.) since we expect downtime. Notifying Slack as patching is scheduled, beginning, and ending is a good idea as well.
While the solution below is certainly not the most refined and is pretty basic bash scripting, it does the trick for many patching needs. I’ll be sure to include “gotchas” we encountered as I go as well!
Getting started
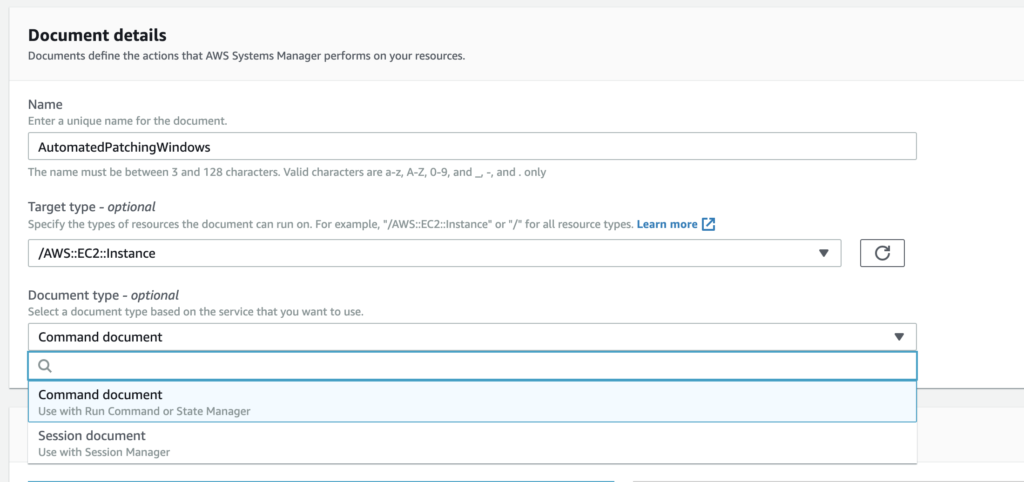
First, in the Documents section you will need to select “Create command or session” to start a new RunCommand document. Select a name, and the type of target (for most, this will be AWS::EC2::Instance). I’ll be showing how to format your script in JSON, but YAML is ok too.
To start, there are a few points of order to get out of the way at the beginning of your script. This includes things like defining any additional parameters for your script and its environment.
{
"schemaVersion": "2.2",
"description": "Command Document Example JSON Template",
"mainSteps": [
{
"action": "aws:runShellScript",
"name": "ApplyMaintenanceWindow",
"inputs": {
"runCommand": [This part defines the schema version to be used (as of this writing, 2.2 is the latest). You can enter a description of this command if desired. After “description” you will need to include any additional parameters that should be selected when running the command, if any. In an earlier version of our Document, I had “appName” and “appEnv” parameters added, but eventually took these out, as these could be determined dynamically from our tagging structure.
If you choose to add Parameters, here is an example of how you can define appName and appEnv:
{
"schemaVersion": "2.2",
"description": "Command Document Example JSON Template",
"parameters": {
"appName": {
"type": "String",
"description": "(Required) Specify the app name",
"allowedValues": [
"App1",
"App2",
"App3"
]
},
"appEnv": {
"type": "String",
"description": "(Required) Specify the app environment",
"default": "Develop",
"allowedValues": [
"Develop",
"Staging",
"Production"
]
}
},
"mainSteps": [...Gather tags
If you gather tags from your EC2 instances in other methods (such as writing them to a file for parsing) you can use this as a way to determine which instance you are running the command on as well. You can either do this entirely separate from patching (such as upon server build, or deploy of code). Or, you can do this at runtime as well. On AWS, you can use cURL to gather instance metadata, and use this to your benefit:
#!/usr/bin/env bash
# Requires aws cli to be installed and proper ec2 roles to read ec2 tags
# Requires sudo permissions to right to /etc/
INSTANCE_ID=`curl http://169.254.169.254/latest/meta-data/instance-id 2>/dev/null`
REGION=`curl http://169.254.169.254/latest/meta-data/placement/availability-zone 2>/dev/null | sed 's/.$//'`
aws ec2 describe-tags --region $REGION --filter "Name=resource-id,Values=$INSTANCE_ID" --output=text | sed -r 's/TAGS\t(.)\t.\t.\t(.)/\1="\2"/' > /etc/ec2-tags
This script will write the tags to the /etc/ec2-tags path on your server, which can be read later.
Back in our Document, we can use that /etc/ec2-tags output (or you can use it within your Document as well if you like).
"mainSteps": [
{
"action": "aws:runShellScript",
"name": "ApplyMaintenanceWindow",
"inputs": {
"runCommand": [
"#!/bin/bash",
"export APPENV=$(grep \"Environment\" /etc/ec2-tags | cut -d'\"' -f2)",
"export APPNAME=$(grep \"AppName\" /etc/ec2-tags | cut -d'\"' -f2)",
"export INSTANCE_ID=$(grep \"Name\" /etc/ec2-tags | cut -d'\"' -f2)",
...Here we are defining the value of some variables that we will be using later in the script, to notify our maintenance windows/monitoring tools: the app environment, app name, and the instance ID (given by AWS).
Scheduling time frames
Now that we have identified which applications and environments are being patched, we need to identify timing. We should define what time the patching will begin, and end, for our notification and monitoring tools.
In my example, I want to schedule and notify for the maintenance 24 hours in advance. The tools I’ll be using are Pingdom and StatusPage, but as long as your monitoring tool has an API this is fairly easy to automate as well!
First you have to determine the time format your API accepts. For Pingdom, they accept UNIX timestamps (which we can get with a simple “date +%s” command). StatusPage.io by contrast uses a different and more unique format, so we have it formatted it as it expects to be read.
Quick Tip: We found that no matter the timezone specified in the StatusPage.io dashboard, it always interpreted the timezone as UTC. So to match the correct time (PST), we had to add 8 hours (or 7 hours during daylight savings time).
"export STATUSPAGE_TIME_START=$(date +%C%y-%m-%dT%TZ -d +1day+8hours)",
"export STATUSPAGE_TIME_END=$(date +%C%y-%m-%dT%TZ -d +1day+8hours+15minutes)",
"export PINGDOM_TIME_START=$(date +%s -d +1day)",
"export PINGDOM_TIME_END=$(date +%s -d +1day+15minutes)",
...Set the StatusPage and Pingdom IDs
Now that we have our time frames settled, we also need to tell our script what ID to use for Pingdom, and what ID to use for StatusPage.io. These values are required when making API calls to these services, and will likely be different based on the application name and environment. To do this we can set variables based on our APPNAME and APPENV vars we set earlier:
"if [[ $APPNAME == \"APP1\" && $APPENV == \"Production\" ]]; then",
" export PINGDOM_ID=\"123456\"",
" export STATUSPAGE_ID=\"abc123def456\"",
"elif [[ $APPNAME == \"APP1\" && $APPENV == \"Demo\" ]]; then",
" export PINGDOM_ID=\"NONE\"",
" export STATUSPAGE_ID=\"456def123abc\"",
"elif [[ $APPNAME == \"App2\" && $APPENV == \"Production\" ]]; then",
" export PINGDOM_ID=\"789012,345678\"",
" export STATUSPAGE_ID=\"ghi456jkl789\"",
"elif [[ $APPNAME == \"APP2\" && $APPENV == \"Demo\" ]]; then",
" export PINGDOM_ID=\"012345\"",
" export STATUSPAGE_ID=\"jkl678mno901\"",
"else",
" export PINGDOM_ID=\"NONE\"",
" export STATUSPAGE_ID=\"NONE\"",
"fi",
...Some things to note about the above block:
- We’re setting the values to “NONE” if there isn’t a Pingdom or StatusPage ID for the specific app and environment – this is also the default value if the app name and environment name don’t match the combinations presented, in our “else” clause.
- If there are multiple Pingdom checks that should be paused during this patching window, you can enter the two IDs separated by a comma (no space) – see “App2 Production” for an example.
Making the API calls
Now that we have all the proper context we can make the API calls. There will be a few sets of API calls:
- First we will notify Slack/Microsoft Teams that patching will begin in 24hrs, and schedule the maintenance windows in Pingdom and Statuspage.
- Next we will give an hour warning to Slack/Microsoft Teams that the patching will begin soon.
- At the 24 hour mark we will send a notice to Slack/Microsoft Teams that the patching is beginning – Pingdom and Statuspage windows will automatically begin.
- We will run the AWS-RunPatchBaseline command, which involves a reboot of the system.
- After patching completes, we will notify Slack/Microsoft Teams that the patching has completed, and list the packages updated.
Patching Scheduled Notifications
Now for the fun part: making the API calls. You will need to replace the OAuth (StatusPage), Bearer (Pingdom), and webhook URL (Microsoft Teams) based on the API tokens and webhooks for your own environments.
"# Add StatusPage notification of scheduled maintenance",
"if [[ $STATUSPAGE_ID != \"NONE\" ]]; then",
" curl -X POST 'https://api.statuspage.io/v1/pages/********/incidents' -H 'Authorization:OAuth ********-****-****-****-********' -d \"incident[name]=Scheduled Maintenance for $APPNAME - $APPENV\" -d \"incident[status]=scheduled\" -d \"incident[impact_override]=maintenance\" -d \"incident[scheduled_for]=$STATUSPAGE_TIME_START\" -d \"incident[scheduled_until]=$STATUSPAGE_TIME_END\" -d \"incident[scheduled_auto_in_progress]=true\" -d \"incident[scheduled_auto_completed]=true\"-d \"incident[components][component_id]=under_maintenance\" -d \"incident[component_ids]=$STATUSPAGE_ID\"",
"fi",
"",
"# Add Pingdom Maintenance window",
"if [[ $PINGDOM_ID != \"NONE\" ]]; then",
" curl -X POST 'https://api.pingdom.com/api/3.1/maintenance' -H 'Content-Type: application/json' -H 'Authorization:Bearer ******_******************_*****************' -d '{\"description\": \"Maintenance for '$APPNAME' - '$APPENV'\", \"from\": '$PINGDOM_TIME_START', \"to\": '$PINGDOM_TIME_END', \"uptimeids\": \"'$PINGDOM_ID'\" }'",
"fi",
"",
"# Notify Teams room of upcoming maintenance/patching",
"curl -X POST 'https://outlook.office.com/webhook/*******-***-****-****-***********-****-****-****-************/IncomingWebhook/***********************/********-****-****-****-**********' -H 'Content-Type: application/json' -d '{\"@type\": \"MessageCard\", \"@context\": \"http://schema.org/extensions\", \"themeColor\": \"ECB22E\", \"summary\": \"AWS Patching Window Notifications\", \"sections\": [{\"activityTitle\": \"Patching Scheduled\", \"activitySubtitle\": \"Automated patching scheduled to begin in 24 hours\", \"facts\": [{\"name\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\"}, {\"name\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\"}], \"markdown\": true}]}'",
""
...Note that the last API call (Microsoft Teams) can be replaced with a Slack one if needed as well:
"# Notify Slack room of upcoming maintenance/patching",
"curl -X POST 'https://hooks.slack.com/services/********/********/****************' -H 'Content-type: application/json' -d '{\"attachments\": [{ \"mrkdwn_in\": [\"text\"], \"title\": \"Patching Scheduled\", \"text\": \"Automated patching scheduled to begin in 24 hours\", \"color\": \"#ECB22E\", \"fields\": [{ \"title\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\", \"short\": \"false\"}, { \"title\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\", \"short\": \"false\"}] }] }'",
""
...After sending our API calls we’ll want to sleep for 23 hours until it’s time for our next notification (1 hour warning):
{
"name": "Sleep23Hours",
"action": "aws:runShellScript",
"inputs": {
"timeoutSeconds": "82810",
"runCommand": [
"#!/bin/bash",
"sleep 23h"
]
}
},
...Quick Tip: We noticed that the longest “timeoutSeconds” will allow is 24 hours (86400 seconds). If you set it higher than that value, it defaults to 10 minutes (600 seconds).
One-hour Notifications
"name": "NotifySlack1Hour",
"action": "aws:runShellScript",
"inputs": {
"runCommand": [
"#!/bin/bash",
"export APPENV=$(grep \"Environment\" /etc/ec2-tags | cut -d'\"' -f2)",
"export APPNAME=$(grep \"AppName\" /etc/ec2-tags | cut -d'\"' -f2)"
"export INSTANCE_ID=$(grep \"Name\" /etc/ec2-tags | cut -d'\"' -f2)",
"# Notify room of upcoming maintenance/patching",
"curl -X POST 'https://hooks.slack.com/services/********/********/****************' -H 'Content-type: application/json' -d '{\"attachments\": [{ \"mrkdwn_in\": [\"text\"], \"title\": \"Upcoming Patching\", \"text\": \"Automated patching scheduled to begin in 1 hour\", \"color\": \"#ECB22E\", \"fields\": [{ \"title\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\", \"short\": \"false\"}, { \"title\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\", \"short\": \"false\"}] }] }'"
]
}
},Or for Microsoft Teams:
"# Notify Teams room of upcoming maintenance/patching",
"curl -X POST 'https://outlook.office.com/webhook/********-****-****-****-****************-****-****-****-************/IncomingWebhook/********************/******************' -H 'Content-Type: application/json' -d '{\"@type\": \"MessageCard\", \"@context\": \"http://schema.org/extensions\", \"themeColor\": \"ECB22E\", \"summary\": \"AWS Patching Window Notifications\", \"sections\": [{\"activityTitle\": \"Upcoming Patching\", \"activitySubtitle\": \"Automated patching scheduled to begin in 1 hour\", \"facts\": [{\"name\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\"}, {\"name\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\"}], \"markdown\": true}]}'",
""
]
}
},Now we sleep for one more hour before patching:
{
"name": "SleepAgainUntilMaintenance",
"action": "aws:runShellScript",
"inputs": {
"timeoutSeconds": "3610",
"runCommand": [
"#!/bin/bash",
"sleep 1h"
]
}
},Patching Beginning
{
"name": "NotifySlackMaintenanceBeginning",
"action": "aws:runShellScript",
"inputs": {
"runCommand": [
"#!/bin/bash",
"export APPENV=$(grep \"Environment\" /etc/ec2-tags | cut -d'\"' -f2)",
"export APPNAME=$(grep \"AppName\" /etc/ec2-tags | cut -d'\"' -f2)",
"export INSTANCE_ID=$(grep \"Name\" /etc/ec2-tags | cut -d'\"' -f2)",
"# Notify Teams room of upcoming maintenance/patching",
"curl -X POST 'https://outlook.office.com/webhook/********-****-****-****-****************-****-****-****-************/IncomingWebhook/********************/******************' -H 'Content-Type: application/json' -d '{\"@type\": \"MessageCard\", \"@context\": \"http://schema.org/extensions\", \"themeColor\": \"ECB22E\", \"summary\": \"AWS Patching Window Notifications\", \"sections\": [{\"activityTitle\": \"Patching Beginning\", \"activitySubtitle\": \"Automated patching has started\", \"facts\": [{\"name\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\"}, {\"name\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\"}], \"markdown\": true}]}'",
""
]
}
},Or for Slack:
"# Notify Slack room of upcoming maintenance/patching",
"curl -X POST 'https://hooks.slack.com/services/********/********/****************' -H 'Content-type: application/json' -d '{\"attachments\": [{ \"mrkdwn_in\": [\"text\"], \"title\": \"Patching Beginning\", \"text\": \"Automated patching has started\", \"color\": \"#ECB22E\", \"fields\": [{ \"title\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\", \"short\": \"false\"}, { \"title\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\", \"short\": \"false\"}] }] }'"Followed by the actual patching task, calling upon the existing AWS-RunPatchBaseline document:
{
"name": "installMissingUpdates",
"action": "aws:runDocument",
"maxAttempts": 1,
"onFailure": "Continue",
"inputs": {
"documentType": "SSMDocument",
"documentPath": "AWS-RunPatchBaseline",
"documentParameters": {
"Operation": "Install",
"RebootOption": "RebootIfNeeded"
}
}
},Post-Patching Notification
Now that the patching has occurred we can send some important data to our chat software (Slack or Microsoft Teams) detailing what was updated:
{
"action": "aws:runShellScript",
"name": "NotifyPatchingComplete",
"inputs": {
"runCommand": [
"#!/bin/bash",
"export APPENV=$(grep \"Environment\" /etc/ec2-tags | cut -d'\"' -f2)",
"export APPNAME=$(grep \"AppName\" /etc/ec2-tags | cut -d'\"' -f2)",
"export INSTANCE_ID=$(grep \"Name\" /etc/ec2-tags | cut -d'\"' -f2)",
"export INSTALL_DATE=$(date \"+%d %b %C%y %I\")",
"export PACKAGES=\"$(rpm -qa --last | grep \"${INSTALL_DATE}\" | cut -d' ' -f1)\"",
"",
"# Notify Slack room that patching is complete",
"curl -X POST 'https://hooks.slack.com/services/********/********/****************' -H 'Content-type: application/json' -d '{\"attachments\": [{ \"mrkdwn_in\": [\"text\"], \"title\": \"Patching Complete\", \"text\": \"Automated patching is now complete\", \"color\": \"#2EB67D\", \"fields\": [{ \"title\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\", \"short\": \"false\"}, { \"title\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\", \"short\": \"false\"}, { \"title\": \"Packages Updated\", \"value\": \"'\"${PACKAGES}\"'\", \"short\": \"false\" }] }] }'"
]
}
}
]
}Or for Teams:
"# Notify Teams room that patching is complete",
"curl -X POST 'https://outlook.office.com/webhook/********-****-****-****-****************-****-****-****-************/IncomingWebhook/********************/******************' -H 'Content-Type: application/json' -d '{\"@type\": \"MessageCard\", \"@context\": \"http://schema.org/extensions\", \"themeColor\": \"2EB67D\", \"summary\": \"AWS Patching Window Notifications\", \"sections\": [{\"activityTitle\": \"Patching Complete\", \"activitySubtitle\": \"Automated patching is now complete\", \"facts\": [{\"name\": \"App Name\", \"value\": \"'$APPNAME' - '$APPENV'\"}, {\"name\": \"Instance Name\", \"value\": \"'$INSTANCE_ID'\"}, {\"name\": \"Packages Updated\", \"value\": \"'\"${PACKAGES}\"'\"}], \"markdown\": true}]}'",
""Note how we’re getting the packages updated from our rpm -qa --last command, and using grep to find the packages updated in the last hour – this generates the list of $PACKAGES that our command receives and sends to Slack/Teams.
Quick tip: Because the list of packages is separated by a new line, we have to wrap it in single and double quotes (e.g. ‘”${PACKAGES}”‘) so that it’s interpreted properly.
Maintenance Windows
Now that we’ve completed our script, we’ll want to ensure it runs on a specified patching schedule. For my team, we patch different environments different weeks, and build patching windows based upon that timeframe. In AWS Systems Manager, you can use several building blocks to ensure the right groups get patched together, at the right times:
- Resource Groups: Use these to group like-instances and resources together. For example, I use resource groups to group instances with the same tags (e.g. Environment=Develop and AppName=App1).
- Target Groups: When you create a Maintenance Window, you can create Target Groups based on Resource Groups, Tags, or specifying literal Instance IDs. I recommend Resource Groups, as (at least for me) the Tags have been hit or miss in identifying the right resources.
- Registered Tasks: The last step in creating a Maintenance Window is to register tasks to that window. In my case I registered tasks for each Target Group I created, because the system wouldn’t let me tag more than a few Target Groups in one task registration.
Some gotchas about your maintenance windows:
- Only 5 maintenance windows can be executing at once. This was a problem for us since we had originally set a maintenance window for each app/env, and it amounted to far more than 5. Since our script is 24hrs long, that’s a fair amount of time to be restricted.
- The cron/rate expressions are a little different. It’s not quite the same as a standard cron expression you’d use in crontab. For example, to run my window at 12:30am on the 4th Friday of every month, I used the following expression:
cron(0 30 0 ? * FRI#4 *)– standing for second, minute, hour, day-of-month, month, day-of-week, year. So if I wanted 12:30:25am on the 1st and 15th of August, I’d usecron(25 30 0 1,15 8 * *). - The cron rates for Maintenance Windows and Associations are different. What is accepted for Associations vs Maintenance windows in terms of cron rate are defined in the AWS docs here: https://docs.aws.amazon.com/systems-manager/latest/userguide/reference-cron-and-rate-expressions.html
Conclusion
This script was a bit tricky to pull together with all the right elements and gotchas, especially since some are not documented much (if at all) in the AWS docs thus far. However, the end results have been absolutely worth the trouble! Systems Manager is a tool that AWS has been putting a lot of work into of late, and the improvements are wonderful — they’re just not fully documented quite yet. I hope my learning helps you in your own journey to automated patching! This has made our patching and compliance cycles painless, visible to the right parties, and auditable. Have any tips, tricks, or experiences you’d like to share? Leave a comment, or contact me.