Defining Segmentation Faults
First, let’s look at the Wikipedia definition for Segmentation faults:
“A segmentation fault occurs when a program attempts to access a memory location that it is not allowed to access, or attempts to access a memory location in a way that is not allowed (for example, attempting to write to a read-only location, or to overwrite part of the operating system).”
That may sound like a bunch of jargon, so if you’re just as confused as before I don’t blame you. The truth is, Segmentation faults are one of the most confusing topics to understand, much less troubleshoot.
Here’s how I understand Segmentation faults:
- A request/process reached into some Memory on your server that wasn’t allocated to it
- Or, a process tried to access Memory in a way that was not allowed
Most often I see Segmentation faults in situations of a Memory leak, or something conflicting with your platform’s rules. The rules could include allowing reads/writes to specific ports, specific conditions of accessing those ports, or security rules blocking one part of the filesystem from reaching into another.
Are Segmentation Faults Happening?
So now that we’ve defined Segmentation faults, how do you know if they’re happening? Usually you’ll see it in your server’s error.log file. For example, here’s an Apache error log with Segmentation faults:
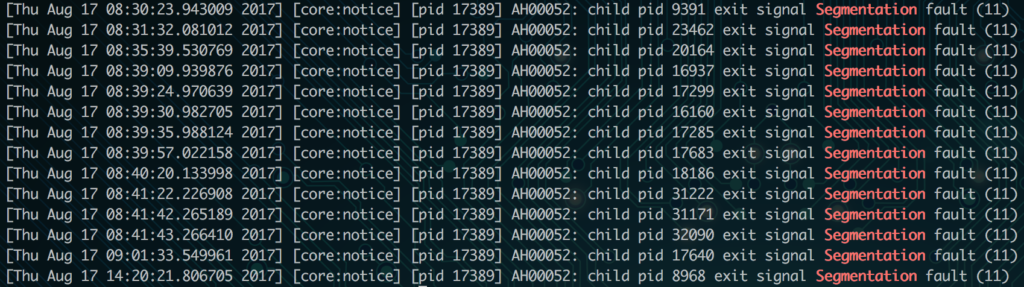
Segmentation faults could potentially happen with any program, not necessarily just Apache. For web servers that use Apache or a combination of Nginx and Apache though, this will be the most common place to look. If another application is running into errors, that service’s error.log file will be the place to look.
Diagnosing Segmentation Faults
Unfortunately, most servers don’t offer a great way to see what’s happening with your Memory. As a result Segmentation faults can be extremely difficult to pin down. If you’re lucky enough to use both Apache and Nginx, most likely you’re using Nginx as a proxy server. In this case, your Nginx error logs will offer a little more information:
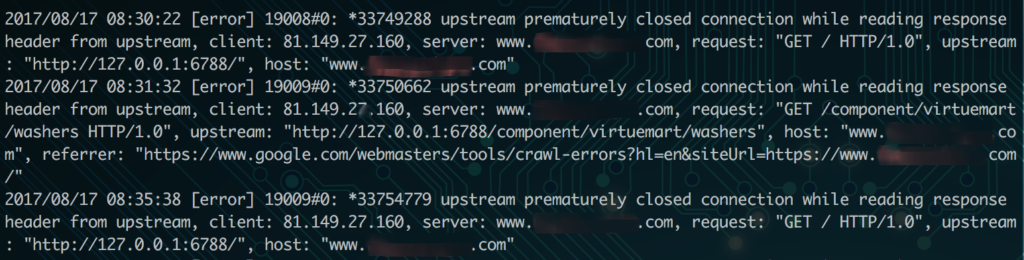
If you’re using a proxy server, you’ll see “upstream connection” errors. This is because Nginx has passed the request to Apache to be served, but the Segmentation fault caused the request to be killed. Nginx is still waiting for the response, so when it’s killed it receives the upstream error. Luckily Nginx logs a little more about the request itself, to offer some more context:
- The date and time
- IP of the client that made the request
- URL of the request
- Port it was routed to
- HTTP Referrer
All of this contextual information can help you narrow down the issue. For example, if I see that the port these requests were routed to only accepts read requests and I see a request that’s likely doing a write request, that explains my issue. I’d need to be sure to route the request to a read/write port instead. Or, if I see that the requests are all from a specific IP address or a specific page, I can dig into the elements that are specific to it to diagnose the issue.
If you don’t have these logs to guide you, you’ll probably need to use either a strace or a core dump. Both of these can be pretty nebulous to read, so tread with caution.
strace
Use a strace when you can reliably replicate the issue. This method traces all the calls and system files being made by the request. It’s best to store the output in a file, so you’d probably want to use a method like this:
sudo strace -p 17389 -o segfault_trace.txt
In the above example, the -p is to trace a specific process ID (or PID for short). You can find this by running the following:
$ ps -C apache2 PID TTY TIME CMD 8225 ? 00:00:01 apache2 8292 ? 00:00:00 apache2 17389 ? 00:07:21 apache2 27732 ? 00:00:06 apache2
And the -o flag in the example says to store the output to the “segfault_trace.txt” file. Storing it to a file makes it easier to search through the text output for any errors or indicators.
core dumps
Using a core dump can also help diagnose a segmentation fault. In this method you first need to have “core dumps” enabled on your server. From there when Segmentation faults are triggered, the core dump will include information about where the Memory was allocated and what issue with the Memory occurred. Check out this overview of how to read the core file that was dumped for more help.
There you have it – some helpful ways to diagnose a Segmentation fault issue. Have more questions about Segmentation faults? Are there other scenarios where you’ve run into Segmentation faults? Let me know in the comments, or contact me.
This is pure gold. Segmentation faults are super unintuitive for devs who are new to server-side debugging. This is invaluable.