What is a header?
Whether you’re using a caching mechanism on your site’s server or not, Cache-Control headers are important to your site’s scalability and your end-user’s experience. Caching, or storing a copy of the completed request, can drastically help limit what requests your web server actually has to serve. But before we dive deeper into headers and cache, let’s first define: what are headers?
Headers are bits of contextual information your web browser can send and receive with requests for pages and files. Certain headers are sent with a request, while others are associated with the response you receive back. In this article we’ll be focusing on the “response headers” specifically. However, some of the directives we talk about are available for “request headers” as well.
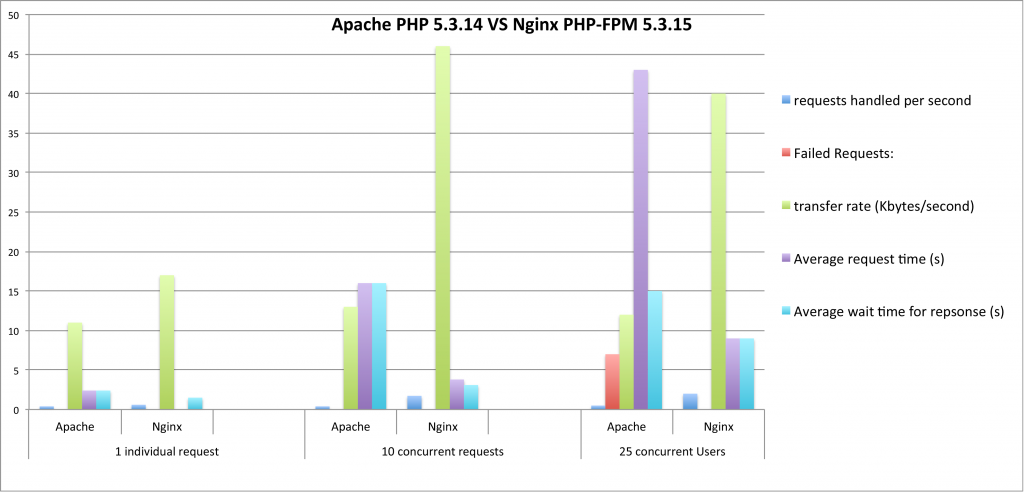
With each request sent on the web, headers are returned. Here’s an example of the headers I get from my own domain:
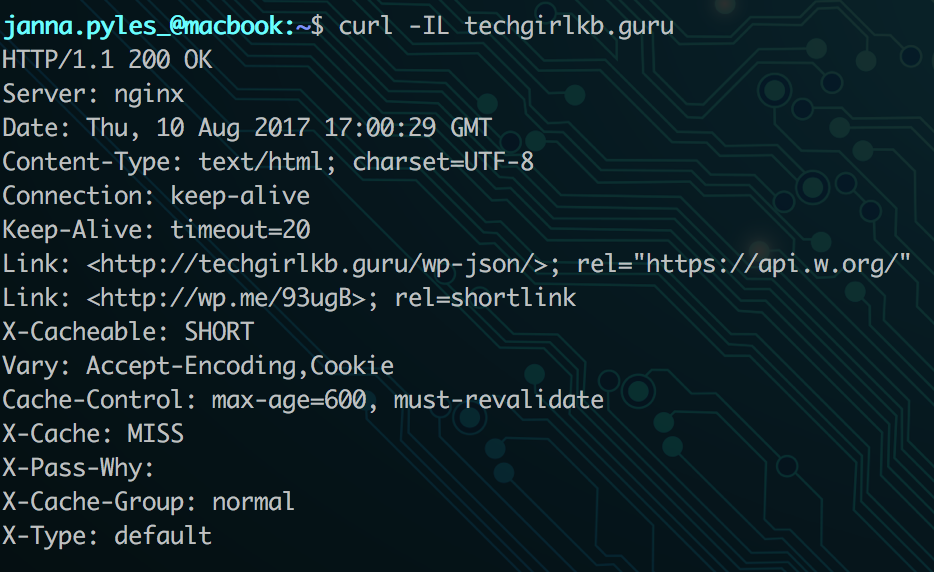
The response headers tell me some information about my request.
HTTP/1.1 200 OK – This is the HTTP response code. It tells me whether my request was successful (200), redirected (301/302), received an error (500), or forbidden (403). There are tons of different status codes you might receive. Check out the full list for more information.
Server: Nginx – This section tells me the type of server that responded to my request. My site is hosted on a stack that uses Nginx as the web server software.
Date: Thu, 10 Aug 2017 17:00:29 – This is simply the date and time the response was served.
What are Cache-Control headers?
Sites may include many other kinds of headers, but I want to specifically call out two more:
Cache-Control: max-age=600, must-revalidate – This header defines how long my page should be cached for. The number is in seconds, so this example indicates a 10-minute cache time.
X-Cache: MISS – The X-Cache header indicates whether my request is served from cache on the server or not. MISS means my request is not already in cache. It passes to the web server to process, then stores a copy in cache on the way back. The next time I hit my site’s home page within the 10 minute cache window, it will serve it from cache.
What kind of cache are we controlling?
Cache-Control headers are responsible for controlling all caches, including (but not limited to): public, private, and server-level page caches. The Cache-Control header in my example above tells my web browser (Chrome in this case) how long to keep the response in its local browser cache.
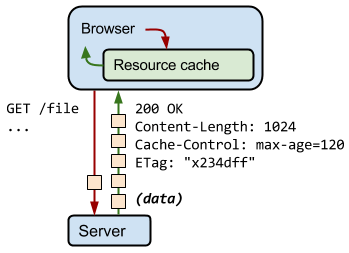
It also tells the Varnish page cache on my server how long to cache the page.
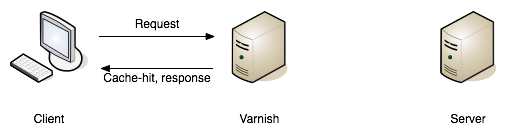
The difference between the two is where the cache exists. In my Chrome browser, I’ve told Chrome to cache the page for 10 minutes with this response header. But what if I purge the cache in Chrome? Varnish page cache on my web server has still cached the response for 10 minutes. So I may still see the cached result from Varnish, unless I purge the page cache on the server too.
What kind of caching directives can I use?
There’s a long list of directives accepted for Cache-Control headers. Some are accepted only for Response headers, while others are also accepted on Request headers.
“public” or “private” directives are accepted only in Response headers. The “public” directive means the response can be cached by any service, regardless of whether you have HTTP Basic Authentication in use on the site or not. Meanwhile, “private” says to only cache in the browser and not in persistent caches, like my server’s Varnish page cache. It means the information on that page should only be cached for that user and not others.
“max-age” directives tell the caching mechanism how long to cache the response before it is considered “stale.” In my example the “max-age” is set to 600 seconds, or 10 minutes. The max-age directive can be used in Request and Response headers.
“must-revalidate” says that once the cached response is considered “stale” (after 10 minutes in my example), it has to be re-fetched/served as new. This directive is only accepted on Response headers.
“no-cache” and “no-store” relate to whether the cached response has to be re-validated by the server (check if the response is the same), and whether the response or content has to be re-downloaded. If “no-cache” is present, the cache mechanism cannot serve the cached response. Instead it must re-check if the response is the same. And if “no-store” is present, the cache mechanism cannot store the data/downloaded content and has to re-fetch the content again. These directives are accepted on both Request and Response headers.
Where do I set these headers?
There are several places you can define caching directives. If you’re one of many on the web using an Apache web server, you can set these directives in the .htaccess file. With an Nginx web server, you can set this in your Nginx configuration. If you use both, you’re probably using Nginx to handle all requests and pass certain ones to Apache. This means you should use the Nginx method of setting these headers.
If you don’t have access to the .htaccess file or Nginx configuration for your site, there are plugins out there which can configure this for you. W3 Total Cache or WP Super Cache both work great for this. If you’re using a host that offers server-level page cache like WP Engine, they take care of the configuration for you.