What is Content Injection?
Content Injection, otherwise known as Content Spoofing, is the act of manipulating what a user sees on a site by adding parameters to their URL. This act is a known form of attack on a website. While Content Injection and XSS (Cross Site Scripting) Attacks are similar, they differ in a few key ways. Firstly, XSS attacks specifically target users by using <script> parameters, mainly using JavaScript. Content Injection by comparison mainly relies on adding parameters to the end of a static URL (/login.php for example).
Here’s a basic example:

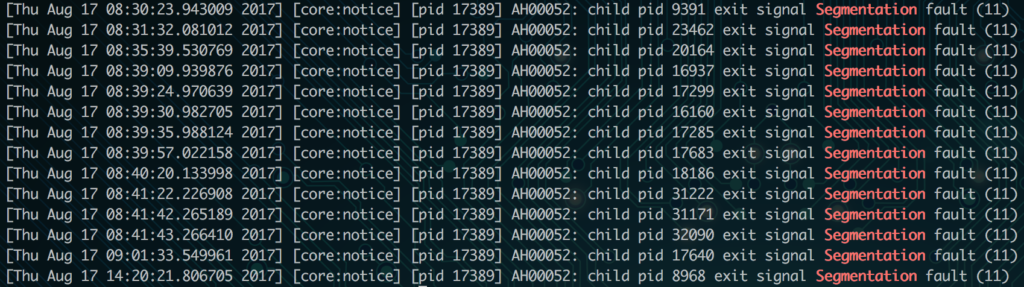
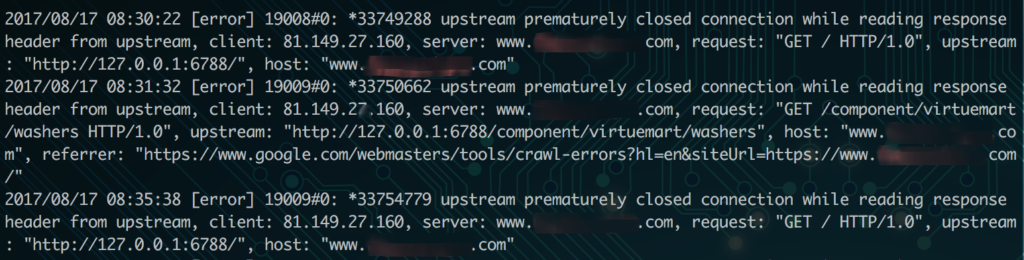
For static files like error pages (in this case a 400 error), attackers can manipulate the text on the page to say what they want. You’ll see in the URL bar that the attacker added extra text to the URL which made the error page print the text since it was part of the URL. Notice, they couldn’t make “www.hackersite.com” actually a clickable link in the basic output which is a good sign. But, easily misled visitors may still try to navigate to “www.hackersite.com” based on the text on this page. The general intent of content injection is usually phishing. Or in other words, getting users to enter their sensitive information by misleading them.
So what’s the fix?
In the interest of protecting your site from content injection on static files like the above, you’d want to use the “AllowEncodedSlashes” directive in Apache like so:
AllowEncodedSlashes NoDecode
With this directive you’re telling Apache to not necessarily show a 404 when “encoded slashes” like %2F and %5C in the URL are added, but instead to show the actual page that *should* have come up. Here’s an example from one of my own sites, with and without encoded slashes set to NoDecode:
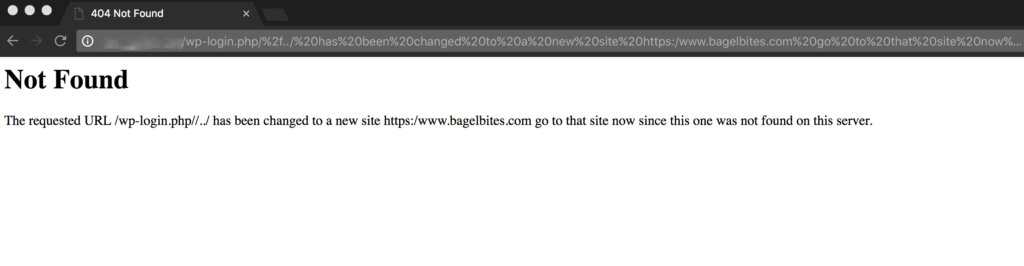
And with the NoDecode directive set:
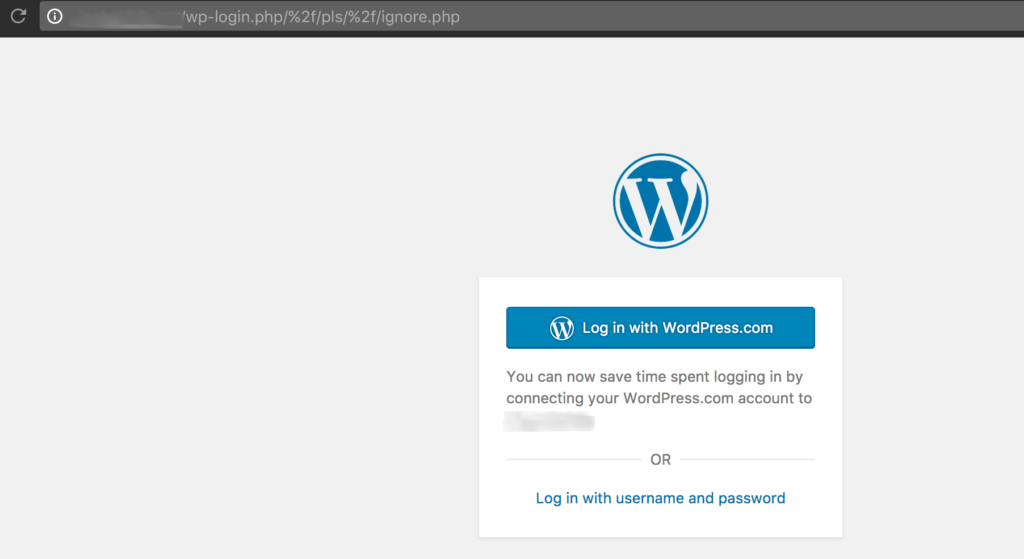
So, using the NoDecode option I’m able to let my users see the correct page, even if someone tried to manipulate the URL to print other text.
Another alternative would be to rewrite static files to your WordPress theme’s 404 page. This way users see your custom page instead of the default white-text static error pages (since they can be manipulated as we saw). This isn’t always the best option for all sites though. It all depends on how you want to handle requests with extra content added to the end.
These types of content injection are usually pretty low-risk. This is because all the attacker can do is manipulate text on specific files. If your site is being affected by XSS though, to where they are able to inject URL links and formatting on a page, that is a more serious concern. Use this guide to help prevent XSS on your site.
That’s all, folks! Have more input on content injection? More tips or tricks? Want to hear more? Let me know in the comments or contact me.