If you’ve ever run into 502, 503, or 504 errors (we’ll refer to them as 50x errors from here on out), you probably know how frustrating they can be to troubleshoot. Learn what each means in this article!
What are 50x errors?
Let’s start at the beginning: what does a 50x error mean? According to the HTTP Status Code guide, here’s what each translates to:
502 Bad Gateway: “the server, while acting as a gateway or proxy, received an invalid response from the upstream server“
503 Service Unavailable: “the server is not ready to handle the request.”
504 Gateway Timeout: “the server, while acting as a gateway or proxy, cannot get a response in time.”
Those descriptions, unfortunately, aren’t specific enough to be very useful to most users.
Here’s how I would describe these errors:
A service (whichever service first received the request) attempted to forward it on to somewhere else (proxy/gateway), and didn’t get the response it expected.
The 502 error
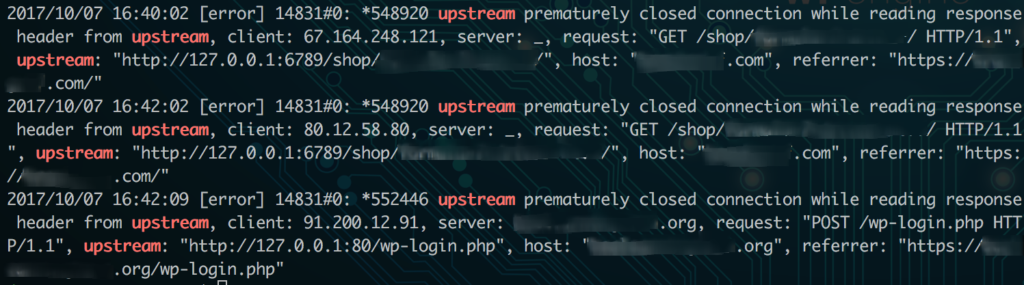
In the case of a 502 error, the service which forwarded the request onward received an invalid response. This could mean that the request was killed on the receiving service processing the request, or that the service crashed while processing it. It could also mean it received another response that was considered invalid. The best source to look would be in the logs of the service that received the request (nginx, varnish, etc), and the logs of the upstream service to which it is proxying (apache, php-fpm, etc).
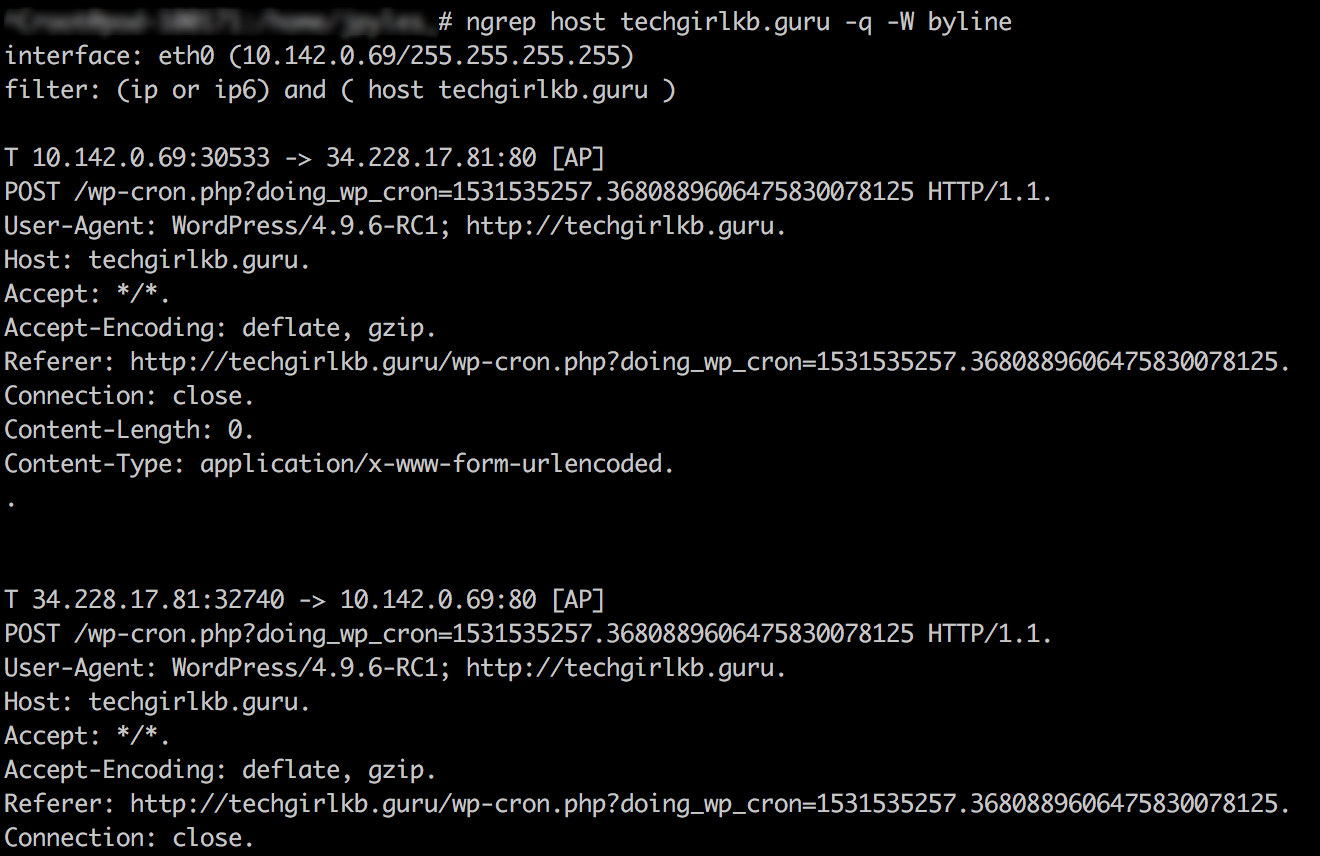
For example, in a current server setup I am managing, I have nginx sitting as essentially a “traffic director” or “reverse proxy” that receives traffic first on the server. It then forwards the request to backend processing service for PHP called php-fpm. When I received a 502 error, I saw an error like this in my nginx error logs:
2019/01/11 08:11:31 [error] 16467#0: *7599 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 10.0.0.1, server: localhost, request: "GET /example/authenticate?code=qwie2347jerijowerdsb23485763fsiduhwer HTTP/1.1", upstream: "fastcgi://unix:/run/php-fpm/www.sock:", host: "example.com"
This error tells me that nginx passed the request “upstream” to my php-fpm service, and did not receive response headers back (i.e. the request was killed). When looking in the php-fpm error logs, I saw the cause of my issue:
[11-Jan-2019 08:11:31] WARNING: [pool www] child 23857 exited on signal 11 (SIGSEGV) after 33293.155754 seconds from start
[11-Jan-2019 08:11:31] NOTICE: [pool www] child 20246 started
Notice the timestamps are exactly the same, confirming this request caused php-fpm to crash. In our case, the issue was corrupted cache – as soon as the cache files were cleared, the 502 error was gone. However, often times you will need to enable core dumps or strace the process to diagnose further. You can read more about that in my article on Segmentation Faults.
A 502 error could also mean the upstream service killed the process (a timeout for long processes, for example), or if the request is proxying between servers, that the destination server is unreachable.
The 503 error
A 503 error most often means the “upstream” server, or server receiving the request, is unavailable. I’ve most often experienced this error when using load balancers on AWS and Rackspace, and it almost always means that the server configured under the load balancer is out of service.
This happened to me once or twice when building new servers and disabling old ones, without adding the new configuration to the load balancer. The load balancer, with no healthy hosts assigned, receives a 503 error because it could not forward the request to any host.
Luckily this error is easily resolved, as long as you have the proper access to your web management console to edit the load balancer configuration! Simply add a healthy host into the configuration, save, and your change should take effect pretty quickly.
The 504 error
Last but not least, a 504 error means there was a gateway timeout. For services like Cloudflare, which sit in front of your website, this often means that the proxy service (Cloudflare in this example) timed out while waiting for a response from the “origin” server, or the server where your actual website content resides.
On some web hosts, it could also mean your website is receiving too much concurrent traffic. If you are using a service like Apache as a backend for PHP processing, it’s likely you have limited threading capabilities, limiting the number of concurrent requests your server can accommodate. As a result, requests left waiting to be processed could be kicked out of queue, resulting in a 504 error. If your website receives a lot of concurrent traffic, using a solution like nginx with php-fpm is ideal in that it allows for higher concurrency and faster request processing. Introducing caching layers is another way to help requests process more quickly as well. In this situation, note that 504 errors will likely be intermittent as traffic levels vary up and down on your website.
Last, checking your firewall settings is another good step. If the “upstream” service is rejecting the request or simply not allowing it through, it could result in a networking timeout which causes a 504 error for your users. Note that in this scenario, you would see the 504 error consistently rather than intermittently as with high traffic.
Conclusion
To wrap things up, remember that a 50x error indicates that one service is passing a request “upstream” to another service. This could mean two servers talking to each other, or multiple services within the same server. Using the steps above will hopefully help in guiding you to a solution!
Have you encountered other causes of these errors? Have any feedback, suggestions, or tips? Let me know in the comments below, or contact me.